
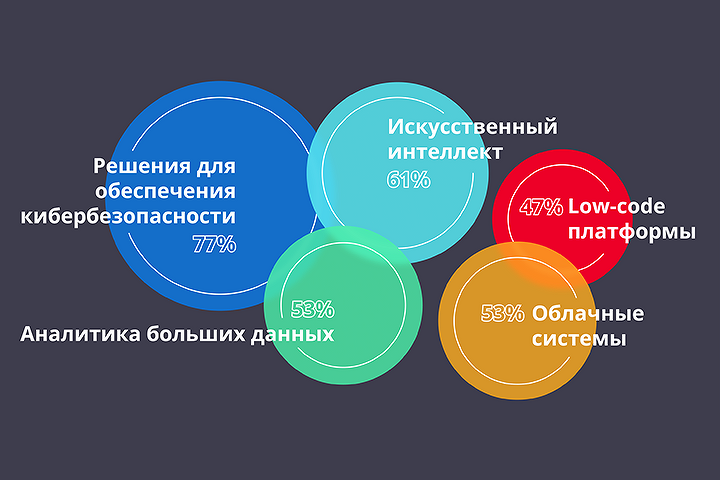














Цифровизация
Мария Захарова, департамент здравоохранения ЯНАО: Телемедицина удобна для жителей сел, особенно тех, куда добираются только на вертолете


Цифровизация
Фарид Нигматуллин, «ВидеоМатрикс»: У видеоаналитики в промышленности большие возможности







Импортонезависимость
Олеся Суханос, «МегаФон ПроБизнес»: Экологическая обстановка стабилизируется за счет новейших технологий







