
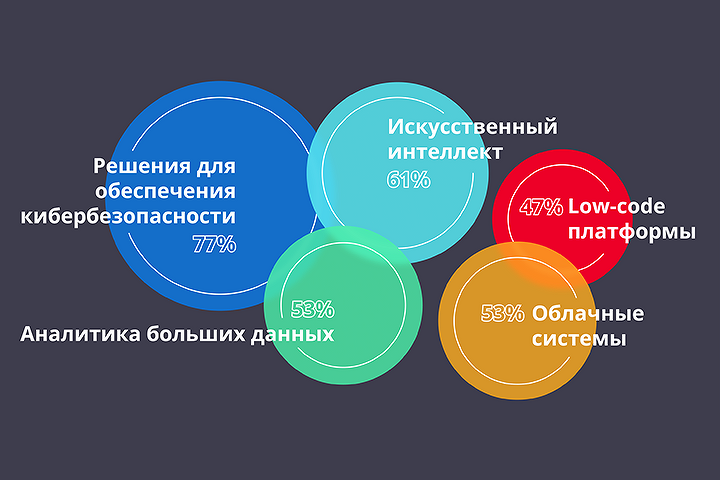









Цифровизация
Мария Захарова, департамент здравоохранения ЯНАО: Телемедицина удобна для жителей сел, особенно тех, куда добираются только на вертолете



Цифровизация
Фарид Нигматуллин, «ВидеоМатрикс»: У видеоаналитики в промышленности большие возможности






Цифровизация
Максим Семёнкин, CodeInside: Рынок от аутсорсинга не отказывается, но активно сокращает его


Импортонезависимость
Олеся Суханос, «МегаФон ПроБизнес»: Экологическая обстановка стабилизируется за счет новейших технологий



Маркет
Виктор Федотов, Softline: Задача импортозамещения выполнена. В нашем облаке есть сегмент на отечественных серверах, ОС и гипервизоре







